DAFTAR ISI
Jaringan
saraf yang dibahas dalam bagian ini adalah arti resmi jaringan saraf untuk
penyimpanan memori skala besar dan pengambilan informasi [Graupe dan
Kordylewski, 1996a, b]. Jaringan ini mencoba untuk meniru proses dari sistem
saraf pusat manusia (CNS), tentang penyimpanan dan pengambilan pola, kesan dan
termasuk proses melupakan dan mengingat. Ia mencoba untuk mencapai hal ini
tanpa bertentangan dengan temuan dari fisiologis dan pengamatan psikologis,
setidaknya dalam input / output. Selanjutnya, yang LAMSTAR (besar Memory
penyimpanan dan pengambilan) Model dianggap sebagai upaya untuk melakukannya
dengan cara komputasi, menggunakan alat dari jaringan saraf dari bagian sebelumnya,
terutama SOM (Self Organizing Map) modul jaringan berbasis, dikombinasikan
dengan alat keputusan statistik. Oleh karena itu jaringan LAMSTAR bukan saja
jaringan tertentu tetapi sistem jaringan untuk penyimpanan, pengakuan,
perbandingan dan keputusan itu dalam kombinasi memungkinkan seperti penyimpanan
dan pengambilan yang harus diselesaikan.
Jaringan
LAMSTAR saraf dirancang khusus untuk aplikasi untuk pemulihan, diagnosis,
klasifikasi, prediksi dan keputusan masalah yang melibatkan jumlah kategori
yang sangat besar. Yang dihasilkan LAMSTAR ( Memory skala besar Penyimpanan dan
Pemulihan) jaringan saraf [graupe 1997, Graupe dan Kordylewski, 1998]
dirancang untuk menyimpan dan mengambil pola dalam komputasi secara
efisien, menggunakan alat jaringan saraf, terutama SOM Kohonen ini (Self
Organizing Peta) modul jaringan berbasis [Kohonen, 1988], dikombinasikan dengan
keputusan statistic alat.
Dengan
struktur seperti yang dijelaskan dalam bagian. 13.2, jaringan LAMSTAR cocok
untuk menangani masalah analitis dan non-analitis di mana data dari banyak
kategori yang berbeda dan di mana beberapa kategori mungkin hilang, di mana
data membutuhkan algoritma yang sangat cepat [Graupe 1997, Graupe dan
Kordylewski, 1998]. Fitur-fitur ini jarang ditemukan,terutama dalam jaringan
saraf lainnya.
LAMSTAR
dapat dilihat seperti dalam sistem cerdas, di mana ahli informasi secara terus
menerus mengembangkan setiap setiap kasus melalui pembelajaran dan korelasi.
Yang unik tentang jaringan LAMSTAR adalah kemampuan untuk menangani data
non-analitis, yang mungkin tepat atau tidak jelas dan di mana beberapa kategori
mungkin hilang. LAMSTAR secara khusus dikembangkan dalam aplikasi untuk masalah
yang melibatkan memori yang sangat besar yang berhubungan dengan banyak
kategori berbeda-beda (atribut), di mana beberapa data yang tepat sedangkan
data lainnya kabur dan mana (untuk masalah yang diberikan) beberapa data
kategori terkadang menjadi benar-benar hilang. Akibatnya, jaringan ini telah
berhasil diterapkan dalam banyak masalah keputusan, diagnosis dan pengakuan di
berbagai bidang.
Prinsip-prinsip
utama dari jaringan saraf (NN) yang umum untuk hampir semua pendekatan jaringan
saraf. Unit dasar saraf atau sel (neuron) adalah salah satu yang
digunakan dalam semua jaringan saraf, seperti yang dijelaskan dalam Bab 2 dan
4.
Untuk keluaran neuron dirumuskan sebagai berikut:
Dimana, f = fungsi aktivasi.
Dengan
menggunakan struktur link bobot untuk keputusannya dan pencarian, jaringan
LAMSTAR yang menggunakan bukan hanya nilai-nilai memori yang tersimpan w (ij)
seperti dalam jaringan saraf lainnya, tetapi juga memori yang saling berkaitan
ini ke modul keputusan dan antara memori sendiri. Pemahaman LAMSTAR ini
dengan demikian didasarkan tidak hanya pada memori (dalam hal bobot yang
penyimpanan) tetapi juga pada hubungan di antara mereka, (dalam hal link
bobot). Hubungan ini (link bobot) merupakan dasar untuk operasi. Dengan Hukum
Hebb ini [Hebb, 1949], interkoneksi bobot (link bobot) menyesuaikan dan
berfungsi untuk membangun ow sinyal trafik neuronal antara kelompok neuron,
maka interkoneksi link-bobot (tidak berat memori penyimpanan) yang berkaitan
dengan trafik, meningkat dibandingkan dengan interkoneksi lainnya [Graupe,
1997; Graupe and Lynn, 1970].
Basic structural elements
 Dimana T merupakan nilai transpos.
Dimana T merupakan nilai transpos.
Gambar 13.1 Blog Diagram LAMSTAR

Gambar 13.2 Dasar arsitektur LAMSTAR: penyederhanaan versi untuk sebagian besar aplikasi
Gambar 13.1 memberikan blok-diagram yang lengkap dan umum dari jaringan LAMSTAR. Sebuah diagram yang lebih mendasar, untuk digunakan di sebagian besar aplikasi di mana jumlah neuron per lapisan SOM tidak besar, sedangkan pada Gambar. 13.2. ini adalah penyederhanaan sedikit arsitektur umum.
Modul
penyimpanan dasar dari jaringan LAMSTAR adalah pengubahan oleh Kohonen terhadap
modul SOM [Kohonen, 1988]. Sesuai dengan tingkat kedekatan bobot penyimpanan di
BAM-akal untuk setiap masukan subword yang sedang dipertimbangkan per setiap
kata masukan yang diberikan kepada jaringan saraf. Di jaringan LAMSTAR
informasi disimpan dan diproses melalui link korelasi antara neuron individu
dalam modul SOM terpisah. Kemampuannya untuk menangani besar jumlah kategori
ini karena penggunaannya perhitungan sederhana link bobot dan oleh penggunaan
fitur dari memori yang hilang. Link bobot adalah mesin utama jaringan,
menghubungkan banyak lapisan SOM modul seperti yang penekanannya pada (co) hubungan
link bobot antara atom memori, bukan pada atom memori (BAM bobot dari modul
SOM) sendiri. Dengan cara ini, desain menjadi lebih dekat dengan pengolahan
pengetahuan dalam biologi sistem saraf pusat daripada praktek di sebagian besar
arti konvensional resmi saraf jaringan. Fitur yang hilang adalah fitur dasar
jaringan biologis yang efisiensi tergantung pada hal itu, seperti kemampuan
untuk menangani set data yang tidak lengkap.
Nilai input dari kode matriks X dinyatakan sebagai berikut:Gambar 13.1 Blog Diagram LAMSTAR

Banyak masukan
subwords (dan sama, banyak masukan untuk hampir semua saraf lainnya Pendekatan
jaringan) dapat diturunkan setelah pre-processing. Hal ini terjadi di masalah
sinyal / image-processing, dimana hanya autoregressive atau diskrit spektral /
parameter wavelet dapat berfungsi sebagai subword daripada sinyal itu sendiri.
Gambar 13.2 Dasar arsitektur LAMSTAR: penyederhanaan versi untuk sebagian besar aplikasi
Gambar 13.1 memberikan blok-diagram yang lengkap dan umum dari jaringan LAMSTAR. Sebuah diagram yang lebih mendasar, untuk digunakan di sebagian besar aplikasi di mana jumlah neuron per lapisan SOM tidak besar, sedangkan pada Gambar. 13.2. ini adalah penyederhanaan sedikit arsitektur umum.
Melupakan diperkenalkan oleh faktor melupakan F (k); seperti yang:

Untuk setiap L Link
berat , di mana k menunjukkan kata masukan k’th dipertimbangkan dan di mana F (k) adalah selisih kecil yang
bervariasi dari waktu ke waktu (lebih k).
Dalam realisasi tertentu LAMSTAR itu, penyesuaian sebagai :F (k) = 0 lebih berturut-turut kata p – 1 dianggap input; (13: 10-a)
tapi
F (k) = bL per setiap kata masukan p’th (13: 10-b)
di mana L adalah link berat dan
b <1 (13: 10-c)
katakanlah, b = 0.5:
Selanjutnya, dalam disukai realisasi Lmax tak terbatas, kecuali untuk pengurangan.
Memperhatikan
rumus pers. (13,9) dan (13.10), Link bobot Li,j hamper nol, jika
tidak berhasil dipilih. Oleh karena itu, korelasi sponsor L yang tidak
berpartisipasi dalam diagnosis / keputusan dari waktu ke waktu, atau
menyebabkan kesalahan diagnosis / keputusan secara bertahap terlupakan. Fitur
melupakan memungkinkan jaringan untuk cepat mengambil informasi terbaru. Karena
nilai link ini menurun secara bertahap dan tidak drop langsung ke nol, jaringan
dapat kembali mengambil informasi terkait dengan link tersebut. Fitur melupakan
jaringan LAMSTAR membantu untuk menghindari kebutuhan untuk mempertimbangkan
jumlah yang sangat link besar.
Tidak ada alasan
untuk menghentikan pelatihan sebagai pertama n set (kata input) data yang hanya
untuk menetapkan bobot awal untuk pengujian set kata-kata input (yang, memang,
menjalankan situasi normal), di LAMSTAR, kita masih bisa melanjutkan pelatihan
ditetapkan oleh set (input-kata oleh input-kata). Dengan demikian, NETWORK
terus menyesuaikan diri selama pengujian dan operasional berjalan rutin
Karena semua informasi dalam jaringan LAMSTAR dikodekan dalam korelasi link, LAMSTAR dapat dimanfaatkan sebagai alat analisis data. Dalam hal ini system menyediakan analisis data input seperti mengevaluasi pentingnya subwords input, kekuatan korelasi antara kategori, atau kekuatan korelasi antara neuron individu.
analisis sistem input data melibatkan dua tahap:
(1) pelatihan dari sistem (seperti yang dijelaskan dalam Sec. 13.4)
(2) analisis nilai-nilai link korelasi seperti yang dibahas di bawah ini.
Karena link korelasi yang menghubungkan cluster (pola) di antara kategori (peningkatan / penurunan) dalam fase pelatihan, adalah mungkin untuk keluar tunggal link dengan nilai tertinggi. Oleh karena itu, cluster dihubungkan dengan link dengan nilai tertinggi menentukan tren dalam data masukan. Berbeda dengan menggunakan data metode rata-rata, kasus terisolasi dari input data LAMSTAR yang Hasil, mencatat fitur melupakan nya. Selanjutnya, struktur LAMSTAR membuat sangat kuat untuk hilang subwords masukan. Setelah fase pelatihan selesai, sistem LAMSTAR tertinggi Link korelasi (link bobot) dan pesan laporan yang terkait dengan kelompok di modul SOM dihubungkan dengan link ini. Link dapat dipilih dengan dua metode:
- sponsor dengan nilai melebihi pra-defined threshold,
- sejumlah nomor link di menghubungkan dengan nilai tertinggi.
Correlation
feature, Pertimbangkan (m) layer yang paling signifikan (module)
terhadap keputusan keluaran (dk) dan (n) neuron yang paling signifikan di
masing-masing (m) lapisan, yang setuju dengan keputusan output yang sama.
(Contoh: misalkan m = n = 4). Kita katakan bahwa korelasi antara subwords
juga dapat ditampung dalam jaringan dengan menetapkan subword masukan spesifik
korelasi itu, subword ini dibentuk oleh pre-processing.
Correlation-Layer
Set-Up Rule: Membangun lapisan SOM tambahan dilambangkan sebagai
CORRELATION-LAYERS λ (p / q, dk), sehingga nilai dari penjumlahan
CORRELATION-LAYERS ini adalah:
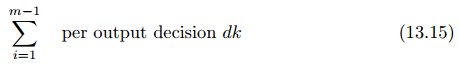
(Contoh: CORRELATION-LAYERS untuk kasus n = m = 4 adalah: λ (1 / 2, dk); λ (1/ 3, dk); λ (1 / 4, dk); λ (2 / 3, dk); λ (2 / 4, dk); λ (3 / 4, dk).)
Selanjutnya,
apabila neuron N (i; p) dan N (j; q) secara bersamaan (yaitu, untuk kata
masukan yang diberikan sama) menang di masing-masing lapisan (p) dan (q) , dan
kedua neuron ini juga milik subset neuron ‘ most significant’ di lapisan ‘ most
significant’ (seperti yang p dan q adalah ‘most significant’ lapisan), maka
kita mendeklarasikan neuron N (i; p / j; q) di λ Korelasi-layer (p / q, dk)
menjadi neuron pemenang dalam korelasi-layer dan kami menghargai / menghukum
output link-berat L (i, p / j, q – dk) sebagai keperperluan untuk setiap neuron
pemenang di setiap lapisan masukan SOM lainnya.
(Contoh: neuron dalam korelasi-lapisan λ (p / q) adalah: N (1, p / 1, q); N
(1, p / 2, q); N (1, p / 3, q); N (1, p / 4, q); N (2, p / 1, q); …N (2, p / 4,
q); N (3, p / 1; q): …N (4, p / 1, q); …N (4, p / 4, q), total neuron mxm di
korelasi-layer).
Setiap
neuron pemenang dalam lapisan korelasi diperlakukan dan berbobot selama setiap
neuron pemenang di lapisan lain (input-SOM) berbobot untuk setiap lapisan
output neuron yang bersangkutan dan diperbarui. Jelas, neuron pemenang (per
kata masukan yang diberikan), jika ada, di lapisan korelasi p / q adalah neuron
N (i; p = j; q) di lapisan yang mana kedua neuron N (i, p) di masukan lapisan
(p) dan neuron N (j, q) pada lapisan (q) adalah pemenang untuk kata masukan
yang diberikan
Interpolation/Extrapolation
via Internal Link: Untuk kata masukan yang diberikan yang berhubungan
dengan keputusan output dk, jika tidak ada masukan subword yang berhubungan
dengan lapisan (p), maka neuron N (i, p) yang memiliki summed-correlation link
tinggi (beban internal link) dengan memenangkan neuron (untuk kata input yang
sama) di lapisan lain v, akan dianggap sebagai interpolasi / ekstrapolasi
neuron di lapisan p untuk masukan kata itu. Namun, tidak ada imbalan / hukuman
yang akan diterapkan untuk neuron selama itu adalah neuron interpolasi /
ekstrapolasi.

di mana v berbeda
dari i dan di mana L (i, p / j, q – dk) menunjukkan bobot link dari
korelasi-layer λ (p / q). Perhatikan bahwa dalam setiap lapisan q hanya ada
satu pemenang neuron untuk kata masukan yang diberikan, dilambangkan sebagai N
(w, q), dimana w mungkin ada disetiap lapisan q’th.
(Contoh: Misalkan p = 3. Jadi pertimbangkan korelasi-lapisan λ (1 / 3, dk);
λ (2 / 3, dκ); λ (3 / 4, dk) sehingga: q = 1, 2, 4. )
redundansi
melalui Korelasi-Layers: Misalkan p menjadi ‘paling signifikan’ lapisan dan
membiarkan saya menjadi ‘paling signifikan’ neuron di lapisan itu. Lapisan p
berlebihan jika untuk semua kata masukan ada ada lagi ‘paling signifikan’
lapisan q sehingga, untuk setiap keputusan output dan untuk neuron setiap N (i,
p), hanya satu korelasi neuron i; p / j, q (yaitu, hanya satu j per
masing-masing seperti i, p) memiliki keluaran-link bobot nol non untuk setiap
dk keputusan output, sehingga setiap neuron N (j, p) selalu dikaitkan dengan
hanya satu neuron N (j, p) di beberapa lapisan p.
(Contoh: Neuron N
(1, p) selalu dikaitkan dengan neuron N (3, q) dan tidak pernah dengan N (1, q)
atau N (2, q) atau N (4, q), sedangkan neuron N (2, p) selalu dikaitkan dengan
N (4, q) dan tidak pernah dengan neuron lain di lapisan (q). Juga, melihat
properti (d) di atas.
Jaringan
LAMSTAR saraf menggunakan fitur dasar dari banyak jaringan saraf lainnya, dan
mengadopsi modul SOM Kohonen ini [Kohonen, 1977, 1984] dengan mereka
asosiatif-memori-pengaturan berdasarkan bobot penyimpanan (wij dalam Bab ini)
dan WTA-nya (Pemenang-Take-Semua) fitur, hal itu berbeda dalam struktur saraf
di setiap neuron memiliki tidak hanya bobot penyimpanan wij (lihat Bab 8 di
atas), tetapi juga link bobot LIJ. Fitur ini langsung mengikuti Hukum Hebb ini
[Hebb, 1949] dan hubungannya dengan Dog eksperimen Pavlov, seperti yang dibahas
di Sec. 3.1. Hal ini juga mengikuti Minsky ini k-garis Model [Minsky, 1980] dan
penekanan Kant pada peran Verbindungen penting dalam \ pemahaman “, yang jelas
berkaitan dengan kemampuan untuk memutuskan. Oleh karena itu, tidak hanya
kesepakatan LAMSTAR dengan dua jenis bobot neuron (untuk penyimpanan dan untuk
rujukan ke lapisan lain), tapi di LAMSTAR itu, bobot Link adalah orang-orang
yang menghitung untuk tujuan keputusan. bobot penyimpanan membentuk atom \
memori “dalam arti Kantian [Ewing, 1938]. keputusan LAMSTAR ini semata-mata berdasarkan
pada link bobot-lihat Sec ini. 13.2 di bawah ini.
LAMSTAR,
seperti semua jaringan saraf lainnya, mencoba untuk memberikan representasi
dari masalah itu harus memecahkan (Rosenblatt, 1961). representasi ini,
mengenai keputusan jaringan, dapat dirumuskan dalam hal pemetaan L nonlinear
dari bobot antara input (vektor input) dan output, yang disusun dalam bentuk
matriks. Oleh karena itu, L adalah fungsi pemetaan nonlinear yang entri adalah
bobot antara input sebuah output, yang memetakan input ke keputusan output.
Mengingat jaringan Back-Propagation (BP), bobot di setiap lapisan adalah kolom
L. Hal yang sama berlaku untuk link bobot LIJ dari L untuk keputusan keluaran
menang dalam jaringan LAMSTAR. Jelas, baik BP dan LAMSTAR, L bukan fungsi
matriks seperti persegi, juga tidak semua kolom yang panjang yang sama. Namun,
di BP, L memiliki banyak entri (bobot) di masing-masing kolom per keputusan
output. Sebaliknya, di LAMSTAR, masing-masing kolom L hanya memiliki satu entri
non-nol. Ini menyumbang baik untuk kecepatan dan transparansi LAMSTAR. bobot
ada di BP tidak menghasilkan informasi langsung tentang apa nilai-nilai mereka
maksud. Dalam LAMSTAR itu, bobot link langsung menunjukkan pentingnya fitur
yang diberikan dan dari subword tertentu relatif terhadap keputusan tertentu,
seperti yang ditunjukkan di Sec. 13,5 bawah. Algoritma LAMSTAR dasar memerlukan
perhitungan hanya pers. (13,5) dan (13,7) per iterasi. Ini melibatkan operasi
hanya penambahan / pengurangan dan thresholding sementara tidak ada perkalian yang
terlibat, untuk lebih berkontribusi kecepatan komputasi yang LAMSTAR ini.
Jaringan
LAMSTAR memfasilitasi analisis multidimensi variabel masukan untuk menetapkan,
misalnya, bobot yang berbeda (penting) untuk item data, menemukan korelasi
antara variabel masukan, atau melakukan identifikasi, pengakuan dan
pengelompokan pola. Menjadi jaringan saraf, LAMSTAR dapat melakukan semua ini
tanpa re-pemrograman untuk setiap masalah diagnostik.
Keputusan
dari jaringan LAMSTAR saraf didasarkan pada banyak kategori data, di mana
sering beberapa kategori yang kabur sementara beberapa yang tepat, dan sering
kategori yang hilang (data set lengkap). Seperti disebutkan dalam Sec. 13.1 di
atas, jaringan LAMSTAR dapat dilatih dengan data yang tidak lengkap atau
kategori set. Oleh karena itu, karena fitur-fiturnya, jaringan LAMSTAR saraf
adalah alat yang sangat efektif dalam situasi hanya seperti itu. Sebagai
masukan, sistem menerima data yang didefinisikan oleh pengguna, seperti, sistem
negara, parameter sistem, atau data yang sangat spesifik seperti yang
ditunjukkan dalam contoh aplikasi yang disajikan di bawah ini. Kemudian, sistem
membangun model (berdasarkan data dari pengalaman masa lalu dan pelatihan) dan
pencarian pengetahuan yang disimpan untuk menemukan yang terbaik pendekatan /
deskripsi untuk fitur / parameter yang diberikan sebagai input data. Input data
dapat secara otomatis dikirim melalui sebuah antarmuka untuk input LAMSTAR ini
dari sensor dalam sistem untuk didiagnosis, mengatakan, sebuah pesawat ke
jaringan yang dibangun di.
Sistem
LAMSTAR dapat dimanfaatkan sebagai:
- Sistem diagnosis medis berbasis komputer [Kordylewski dan Graupe 2001, Nigam dan Graupe 2004, Muralidharan dan Rousche 2005].
- Tool Untuk evaluasi keuangan.
- Alat untuk pemeliharaan industri dan diagnosis kesalahan (pada baris yang sama seperti aplikasi untuk diagnosis medis).
- Alat untuk data mining [Carino et al, 2005].
- Alat untuk browsing dan informasi pengambilan.
- Alat untuk analisis data, klasifikasi, browsing, dan prediksi [Sivaramakrishnan dan Graupe, 2004].
- Alat untuk mendeteksi gambar dan pengakuan [Girado et al, 2004].
- Bantuan Pengajaran.
- Alat untuk menganalisis survei dan kuesioner tentang beragam item.
Semua
aplikasi ini dapat mempekerjakan banyak jaringan saraf lain yang kita bahas.
Namun, LAMSTAR memiliki kelebihan tertentu, seperti ketidakpekaan terhadap
inisialisasi, menghindari minima lokal, kemampuan lupa (ini sering dapat
diimplementasikan dalam jaringan lain), transparansi (bobot Link membawa
informasi yang jelas mengenai bobot link di relatif pentingnya masukan
tertentu, pada korelasinya dengan input lain, pada kemampuan deteksi inovasi
dan redundansi data | melihat Secs 13,5 dan 13,6 di atas).. Yang terakhir
memungkinkan download data tanpa penentuan sebelumnya signifikansi dan membiarkan
jaringan memutuskan untuk dirinya sendiri, melalui link bobot untuk output.
LAMSTAR itu, berbeda dengan jaringan lainnya, dapat bekerja tanpa gangguan jika
set tertentu dari data (input-kata) tidak lengkap (hilang subwords) tanpa
memerlukan pelatihan baru atau perubahan algoritmik. Demikian pula, subwords
masukan dapat ditambahkan selama operasi jaringan tanpa pemrograman ulang saat
mengambil keuntungan dari fitur melupakan nya. Selanjutnya, LAMSTAR yang sangat
cepat, terutama dibandingkan dengan back-propagasi atau jaringan statistik,
tanpa mengorbankan kinerja dan selalu belajar selama berjalan biasa.
Lampiran
13.A memberikan rincian algoritma LAMSTAR untuk Character Recognition masalah
yang juga subjek Lampiran untuk Bab 5, 6, 7, 8, 9, 11 dan 12. Contoh aplikasi
untuk keputusan dan diagnosis masalah medis yang diberikan dalam Lampiran 13.B
bawah.

